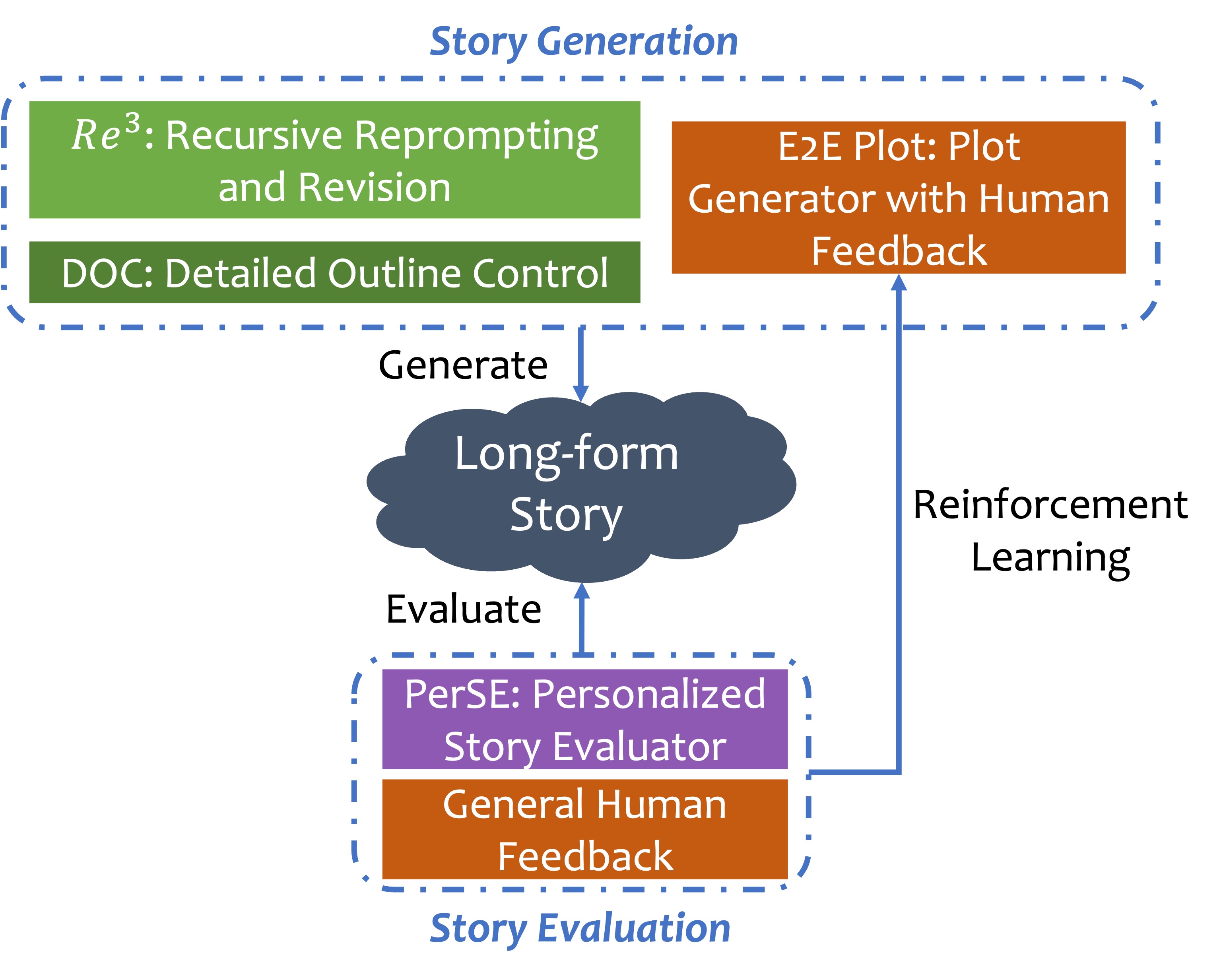
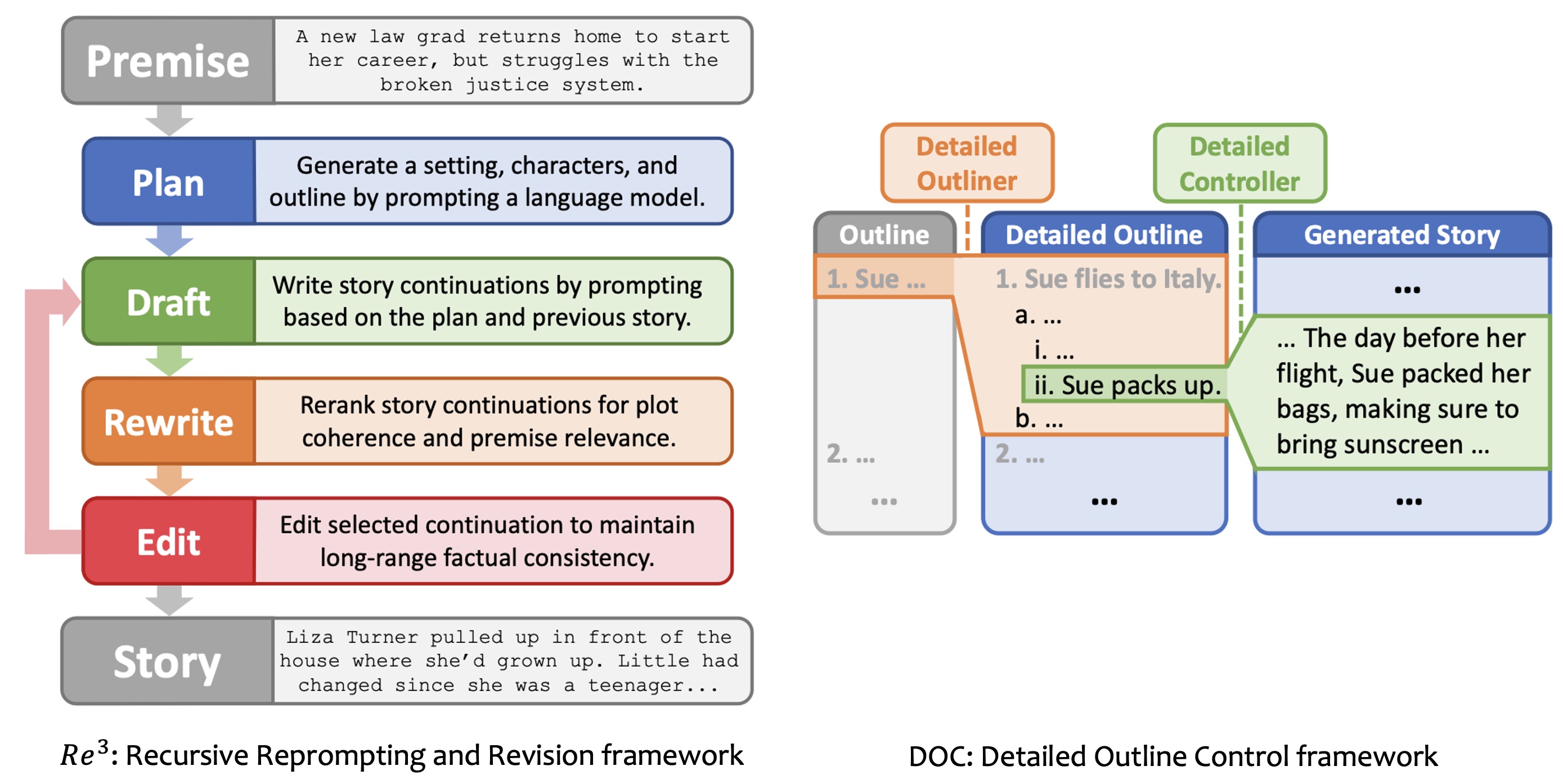
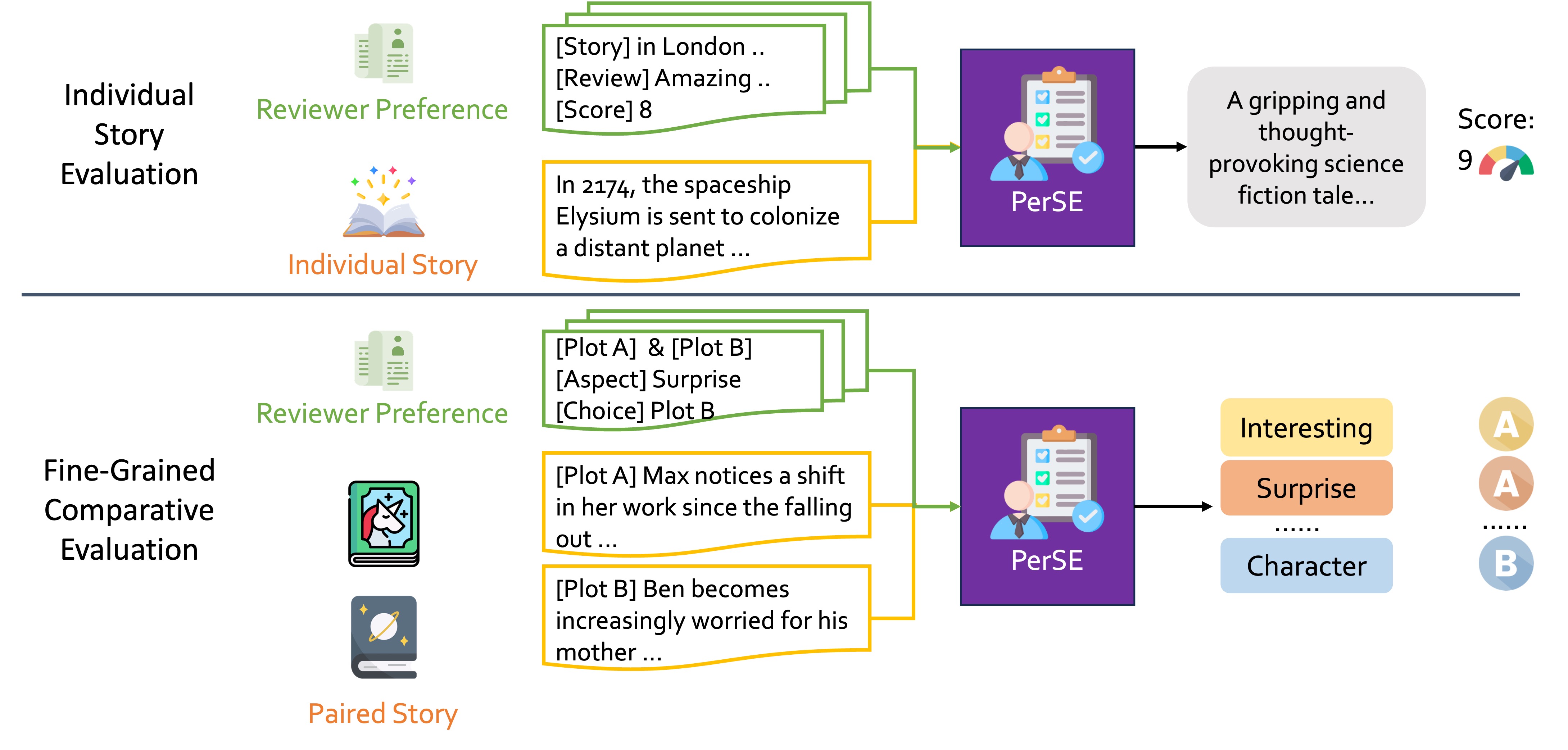
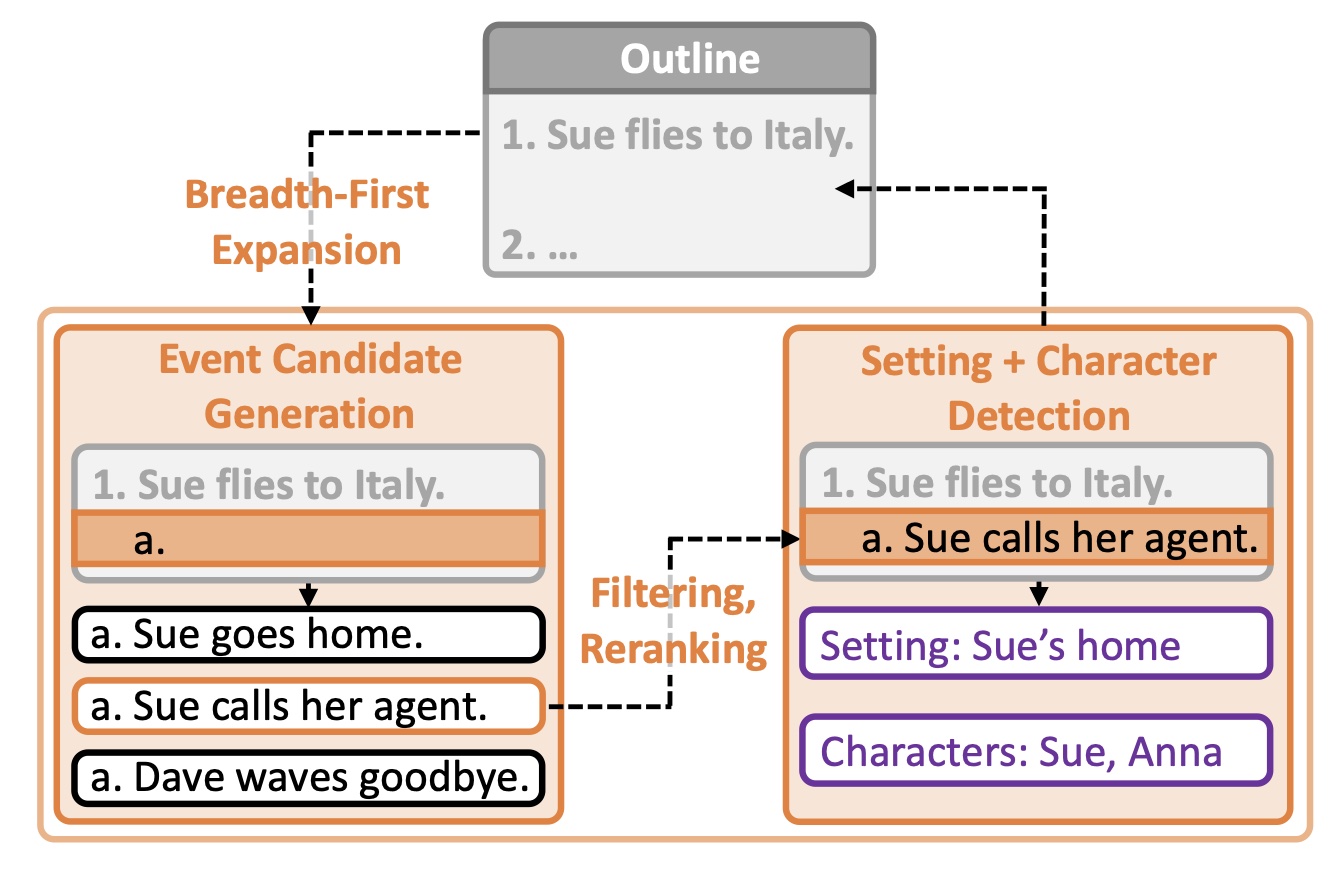
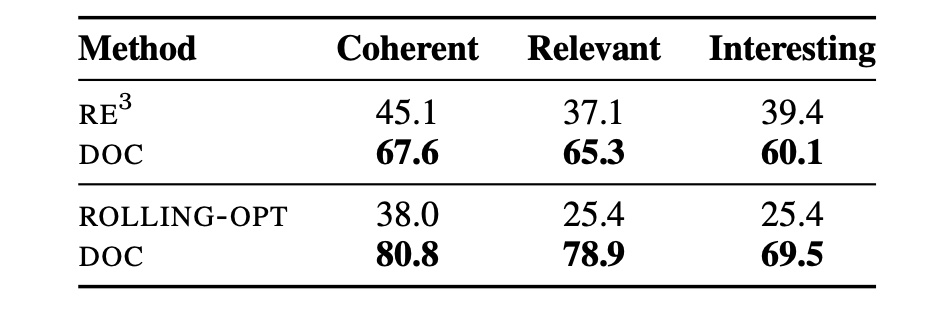
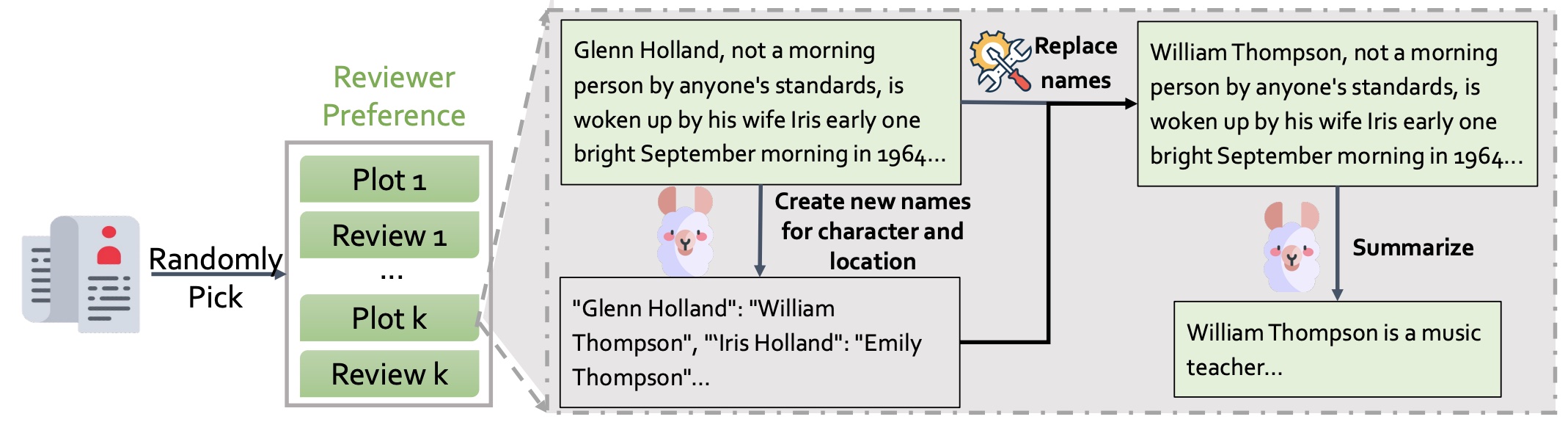
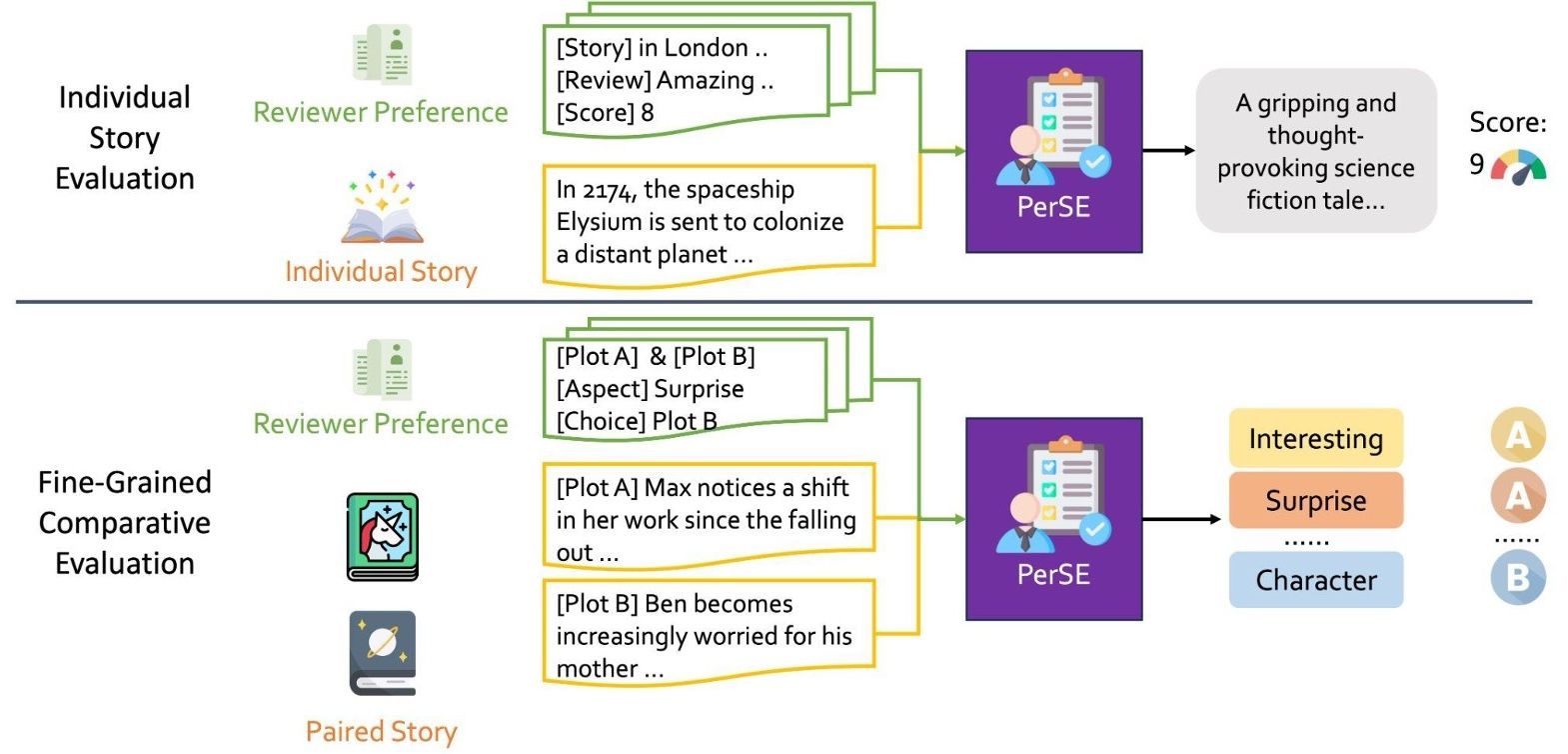
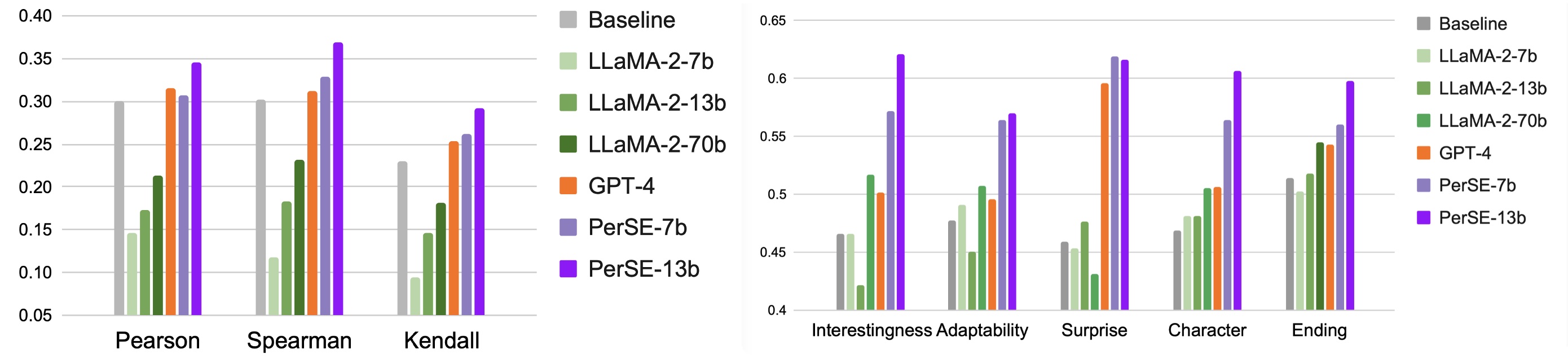
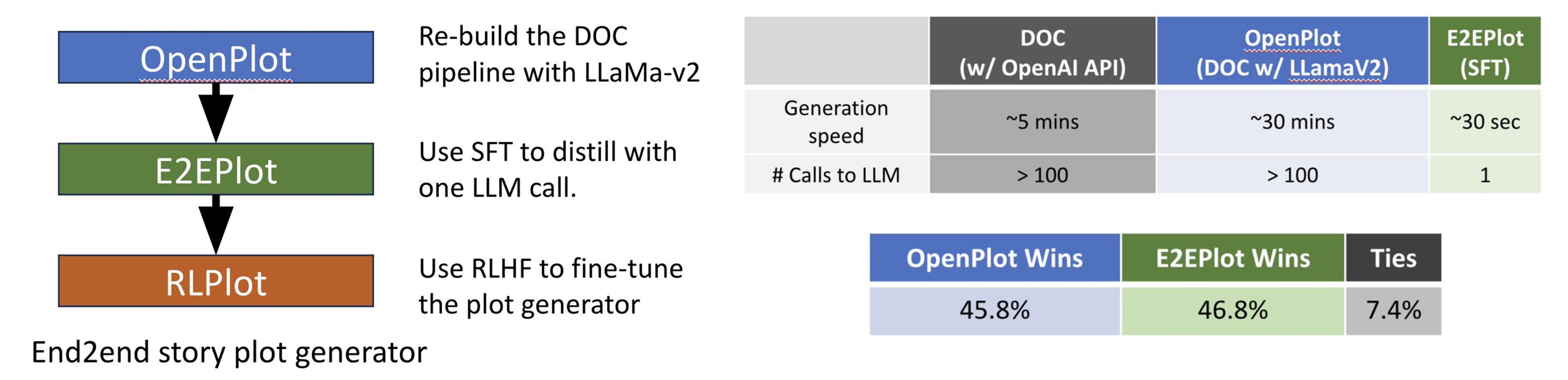
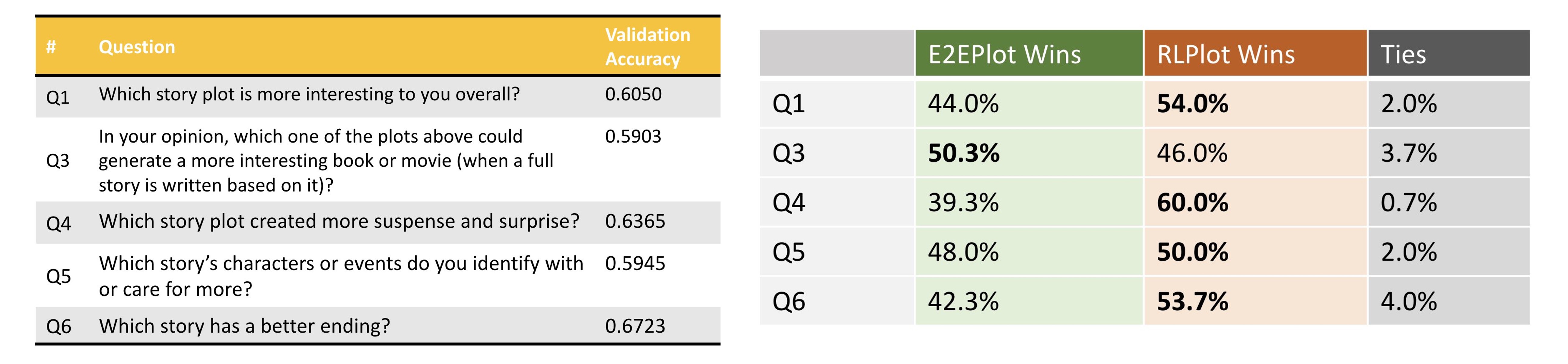
Story plots, while short, carry most of the essential information of a full story that may contain tens of thousands of words. We study the problem of automatic generation of story plots, which includes story premise, character descriptions, plot outlines, etc. To generate a single engaging plot, existing plot generators (e.g., 𝙳𝙾𝙲 (Yang et al., 2022a)) require hundreds to thousands of calls to LLMs (e.g., OpenAI API) in the planning stage of the story plot, which is costly and takes at least several minutes. Moreover, the hard-wired nature of the method makes the pipeline non-differentiable, blocking fast specialization and personalization of the plot generator. In this paper, we propose three models, 𝙾𝚙𝚎𝚗𝙿𝚕𝚘𝚝, 𝙴𝟸𝙴𝙿𝚕𝚘𝚝 and 𝚁𝙻𝙿𝚕𝚘𝚝, to address these challenges. 𝙾𝚙𝚎𝚗𝙿𝚕𝚘𝚝 replaces expensive OpenAI API calls with LLaMA2 (Touvron et al., 2023) calls via careful prompt designs, which leads to inexpensive generation of high-quality training datasets of story plots. We then train an end-to-end story plot generator, 𝙴𝟸𝙴𝙿𝚕𝚘𝚝, by supervised fine-tuning (SFT) using approximately 13000 story plots generated by 𝙾𝚙𝚎𝚗𝙿𝚕𝚘𝚝. 𝙴𝟸𝙴𝙿𝚕𝚘𝚝 generates story plots of comparable quality to 𝙾𝚙𝚎𝚗𝙿𝚕𝚘𝚝, and is > 10× faster (1k tokens in only 30 seconds on average). Finally, we obtain 𝚁𝙻𝙿𝚕𝚘𝚝 that is further fine-tuned with RLHF on several different reward models for different aspects of story quality, which yields 60.0% winning rate against 𝙴𝟸𝙴𝙿𝚕𝚘𝚝 along the aspect of suspense and surprise.